
こんばんは!
運用中のアプリのユーザーが増えてきたある日、RDSのCPU使用率がピーク時に80%前後で推移していることに気づきました。
元々、Lambda+RDSという構成の為、DBのコネクションのプールがされない為に負荷がかかりやすいことは承知していたのですが、流石に見過ごせないレベルだった為に調査をすることになりました。
CPUに負荷をかけた犯人を探す
Performance Insightsを有効化する
まずはRDSインスタンスのPerformance Insightsの設定を有効にします。 RDSインスタンスを選択し、「変更」ボタンから設定値の変更をします。
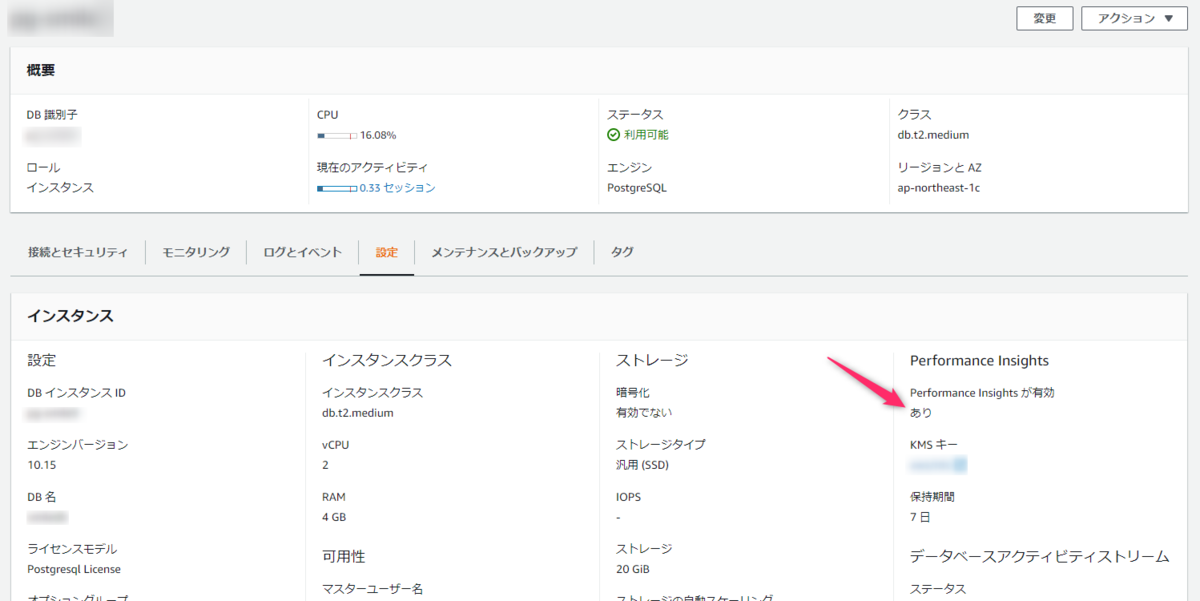
「Performance Insightsを有効にする」にチェックを入れるだけです。

Perfomance Insightsの有効化はダウンタイムを伴いません。 RDSの変更時は項目によってダウンタイムが発生するものとそうでないものがあります。
↓どの項目変更がダウンタイムを伴うのかは以下に載ってます。
Amazon RDS DB インスタンスを変更する - Amazon Relational Database Service
原因となるSQLを突き止める
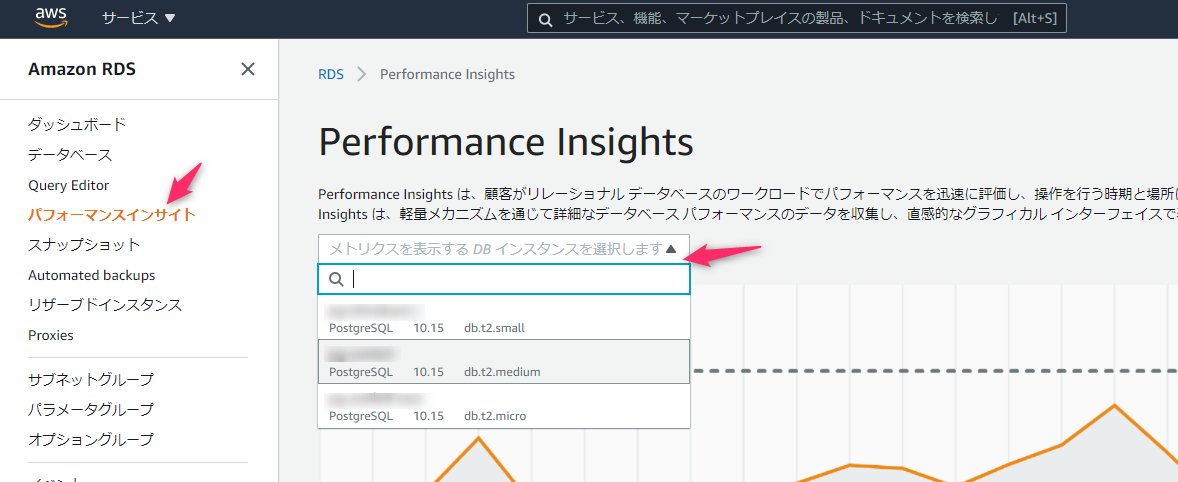
Performance Insightsの画面へ移動し、表示するRDSインスタンスを選択するとグラフでCPU使用率を確認できるようになります。

緑の棒グラフが平均アクティブセッションです。 横に引かれている点線がMax vCPU(インスタンスが許容する最大vCPU)で、これをオーバーしているとCPUの許容量が超えた為にパフォーマンスが低下する可能性が高まります。 Max vCPUはRDSインスタンスの設定により異なります。
グラフのうち詳細に見たい部分をドラッグすると、ドラッグして選択した範囲がズームで表示されるようになりますので、明らかに負荷の高い時間帯を狙ってドラッグしてみてもいいでしょう。
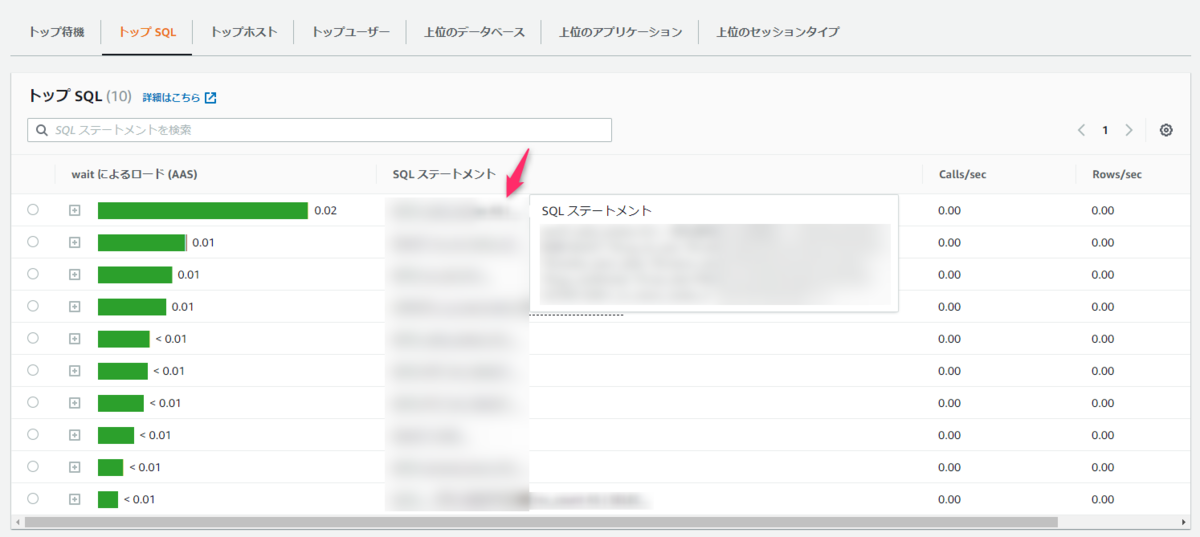
グラフの下部にはCPU使用率の要因となる具体的なSQLのトップ10が表示されます。 SQLステートメント列にはSQL文が表示されているので、ここを確認することでパフォーマンスを悪化させている犯人を特定できるようになっています。
SQLが特定できたら、あとはそれを実行するプログラムをエディタなりで検索して修正するだけです。 ちなみに今回のCPU使用率が高まった原因は、ケアレスミスで必要以上にレコードを取得するようなSQLが頻繁に実行される処理中に仕込まれていたことが原因でした。
ユーザーが増え、レコード全体の総量が増えた為問題が顕在化したようです。

グラフの右上のセレクトボックスは集計項目を変更することができるようになっており、SQL別に色分けして棒グラフを表示させることも可能です。 グラフ下部のトップSQLにも対応した色が付くのでいつ問題のSQLが実行されていたのかが特定しやすくなります。 操作もシンプルで直感的な良い機能だと思います。
あとがき
実は今までRDSを1年以上運用してきたにも関わらず、この機能の存在を見過ごしていました…。 早いところ有効化しておくべきだったと反省しています。😓